Training, Validation, and Test Datasets - Machine Learning
Definitions
- Training Dataset: The sample of data used to fit the model.
- Validation Dataset: The sample of data used to provide an unbiased evaluation of a model fit on the training dataset while tuning the model’s hyperparameters.
- Examples of the hyperparameters can be the number of hidden units, the layers and the layer widths in a neural network.
- Test Dataset: Also called the validation dataset, the sample of dataset that has not been used in training the model. It is used to provide an unbiased evaluation of a final model fit on the training dataset.
- Note: The test dataset can be referred to as the validation dataset if the original data was partitioned into two subsets.
Train-Test Split Evaluation
The train-test split is a method for evaluating the performance of a machine learning model.
The train-test split procedure involves taking a dataset and dividing it into the training and test datasets.
- The first dataset is used to fit the model.
- The second dataset is not used to train the model and the input component of the dataset is provided to the model, then predictions are made and compared to the expected values.
Advice on Model Evaluation
- The evaluation of the model score on the training dataset would result in a biased score.
- The model must be evaluated on the held-out sample to result in an unbiased score of the model.
- It is important that the final model evaluation must be a held-out dataset that was not used for training the model or tuning the model parameters.
Diagrams
Diagram of splitting the dataset into training, testing, and validation datasets:
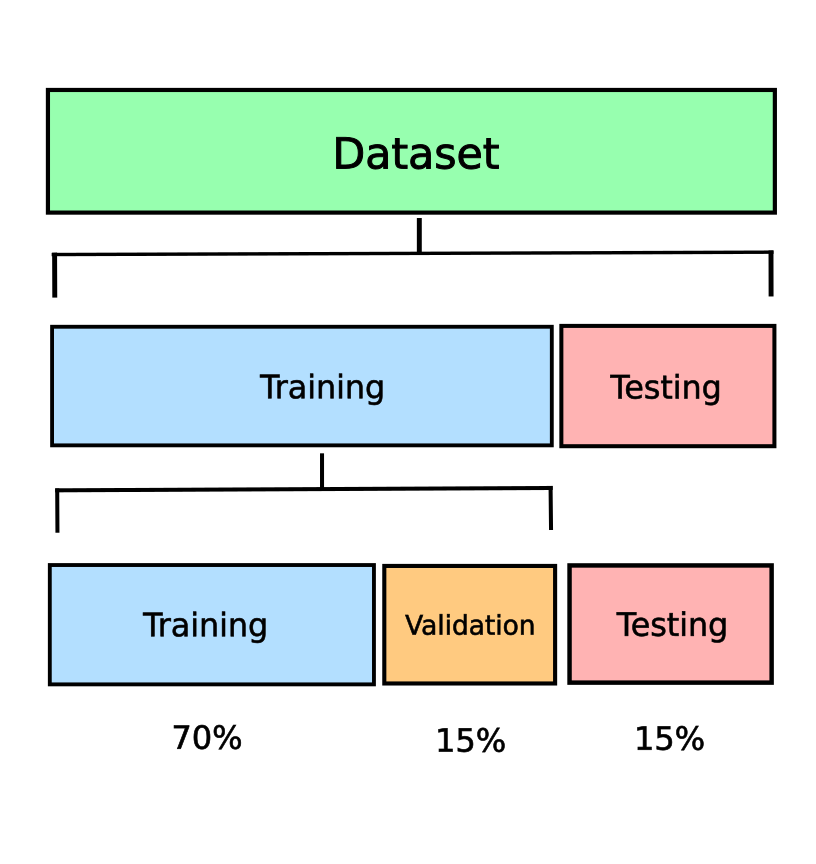
Diagram of splitting the dataset into training and validation datasets:

Resources
- Machine Learning Mastery
- How to Train and Test Data Like a Pro - Data Masters Club
- Training, validation, and test data sets - Wikipedia
- "Train, Validation, Test Split” explained in 200 words - Thaddeus Segura
- How To Do Train Test Split Using Sklearn In Python - GeeksforGeeks
- Train Test Split – How to split data into train and test for validating machine learning models? - machinelearningplus